Transformers para predicción oncológica
Mi tesis de maestría en Data Science. Por qué los Transformers entienden mejor las historias clínicas que cualquier modelo tradicional — y por qué antes de escribir código, escribí un protocolo de anonimización.
Abrí la base de datos y vi más de 20 años de historias clínicas.
Diagnósticos. Laboratorios. Procedimientos. Informes de imagen. Evoluciones médicas. Miles de pacientes. Millones de registros.
Y una pregunta que no me soltó más:
¿Se puede predecir la probabilidad de que un paciente sea oncológico antes de que alguien lo sospeche?
Esa pregunta se convirtió en mi tesis de maestría en Data Science.
Lo que hay detrás de ChatGPT, Claude y Gemini
Hoy millones de personas usan estos modelos. Pocos se preguntan qué hay detrás. La respuesta es una arquitectura: los Transformers.
Lo que me fascinó cuando empecé a estudiarlos es justamente lo que la hace superior a las redes neuronales clásicas y los modelos tradicionales de machine learning: el contexto.
Una red neuronal tradicional procesa datos, pero no entiende relaciones de largo alcance. Los Transformers sí — a través de sus mecanismos de atención, pueden conectar un evento clínico de hace 3 años con lo que pasó ayer.
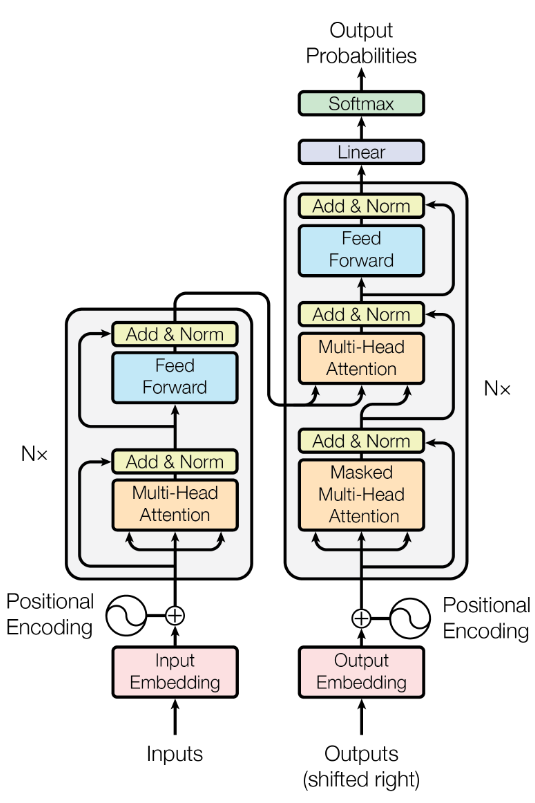
Figura 1 de “Attention Is All You Need” (Vaswani et al., 2017) — la arquitectura Transformer que hoy está detrás de ChatGPT, Claude, Gemini y la mayoría de los LLMs modernos.
De predecir el próximo token a predecir la próxima transacción clínica
Mi tesis no busca predecir el próximo token como hace un LLM. Busca predecir la próxima transacción clínica.
La idea viene de investigaciones recientes que aplicaron Transformers a transacciones financieras para detectar fraude, demostrando que esta arquitectura supera a modelos clásicos como XGBoost, Random Forest y redes neuronales en datos transaccionales.
Mi apuesta es llevar ese mismo enfoque al dominio clínico: tratar la historia de un paciente como una secuencia de transacciones donde cada diagnóstico, cada laboratorio, cada procedimiento es un evento con contexto y significado.
Y quiero ir más allá de la tesis. Mi objetivo es volverme experto en esta arquitectura, seguir de cerca cada variante nueva que aparece, y entender a fondo cómo adaptarla a problemas reales.
Antes del código, la ética
Antes de escribir una línea de código, tuve que escribir un protocolo de anonimización y presentarlo ante un Comité de Ética. Porque trabajar con datos médicos reales tiene una complejidad que va más allá de lo técnico.
Es garantizar disociación irreversible. Es validar k-anonimato para que ninguna combinación de variables identifique a un paciente. Es declarar conflicto de interés porque soy el investigador y el líder de datos al mismo tiempo.
Hubo un momento, armando ese protocolo, en que dejé de ver filas en un dataset. Y empecé a ver pacientes. En detección temprana de oncología, cada mes de ventaja puede cambiar un pronóstico.
Lo que viene
Arranca un camino largo. Voy a ir compartiendo todo lo que aprenda: papers, decisiones de arquitectura, el proceso ético y los resultados.
Si trabajás con ML en salud o te interesa la arquitectura Transformer aplicada a problemas reales — conectemos.
Papers de referencia que están detrás de esta investigación:
- “Attention Is All You Need” (Vaswani et al., 2017) — el paper fundacional de la arquitectura Transformer.
- “Credit Card Fraud Detection Using Advanced Transformer Model” (Yu et al., 2024) — aplicación de Transformers a transacciones financieras con resultados superiores a XGBoost, TabNet y redes neuronales.
¿Te resonó algo?
Sumate a la conversación en el post original de LinkedIn.